pacman::p_load(sf, tidyverse, tmap, spdep, funModeling, plotly, rPackedBar)Take Home Exercise 1
1 Overview
1.1 Getting Started
In the code chunk below, p_load() of pacman package is used to install and load the following R packages into R environment:
sf is use for importing and handling geospatial data in R,
tidyverse is mainly use for wrangling attribute data in R,
tmap will be used to prepare cartographic quality chropleth map,
spdep will be used to compute spatial weights, global and local spatial autocorrelation statistics, and
funModeling will be used for rapid Exploratory Data Analysis
1.2 Importing Geospatial Data
In this in-class data, two geospatial datasets will beused, they are:
geo_export
nga_admbnda_adm2_osgof_20190417
1.2.1 Importing Geospatial Data
First, we are going to import the water point geospatial data (i.e. geo_export) by using the code chunk below.
wp <- st_read(dsn = "data",
layer = "geo_export",
crs = 4326) %>%
filter(clean_coun == "Nigeria")Things to learn from the code chunk above:
st_read()of sf package is used to import geo_export shapefile into R environment and save the imported geospatial data into simple feature data table.filter()of dplyr package is used to extract water point records of Nigeria.
Next, write_rds() of readr package is used to save the extracted sf data table (i.e. wp) into an output file in rds data format. The output file is called wp_nga.rds and it is saved in geodata sub-folder.
write_rds(wp, "data/wp_nga.rds")1.2.2 Import Nigeria LGA Boundary data
Now, we are going to import the LGA boundary data into R environment by using the code chunk below.
nga <- st_read(dsn = "data",
layer = "nga_admbnda_adm2_osgof_20190417",
crs = 4326)Thing to learn from the code chunk above.
st_read()of sf package is used to import nga_admbnda_adm2_osgof_20190417 shapefile into R environment and save the imported geospatial data into simple feature data table.
1.3 Data Wrangling
1.3.1 Recoding NA values into string
In the code chunk below, replace_na() is used to recode all the NA values in status_cle field into Unknown.
wp_nga <- read_rds("data/wp_nga.rds") %>%
dplyr::mutate(status_cle =
replace_na(status_cle, "Unknown"))1.3.2 EDA
In the code chunk below, freq() of funModeling package is used to display the distribution of status_cle field in wp_nga.
freq(data=wp_nga,
input = 'status_cle')The above bar chart provide a brief understanding that the percentage of water-points that are functional in Nigeria is slightly less than 50%. It is crucial thus to dive deeper to determine if there are significant pattern in areas that do not have functional water-points and if the neighbouring areas can support those areas that face scarcity in water supply.
Observe that there are two categories with similar names (i.e. ‘Non-Functional due to dry season’ and ‘Non functional due to dry season’, we will standardize this by changing that later to ‘Non-Functional due to dry season’. We will also group those water-points which are marked ‘Abandoned’ with those that are grouped under ‘Abandoned/Decommissioned’.
wp_nga$status_cle[wp_nga$status_cle == "Non functional due to dry season"] <- "Non-Functional due to dry season"
wp_nga$status_cle[wp_nga$status_cle == "Abandoned"] <- "Abandoned/Decommissioned"We rerun the above code to get the following chart
freq(data=wp_nga,
input = 'status_cle')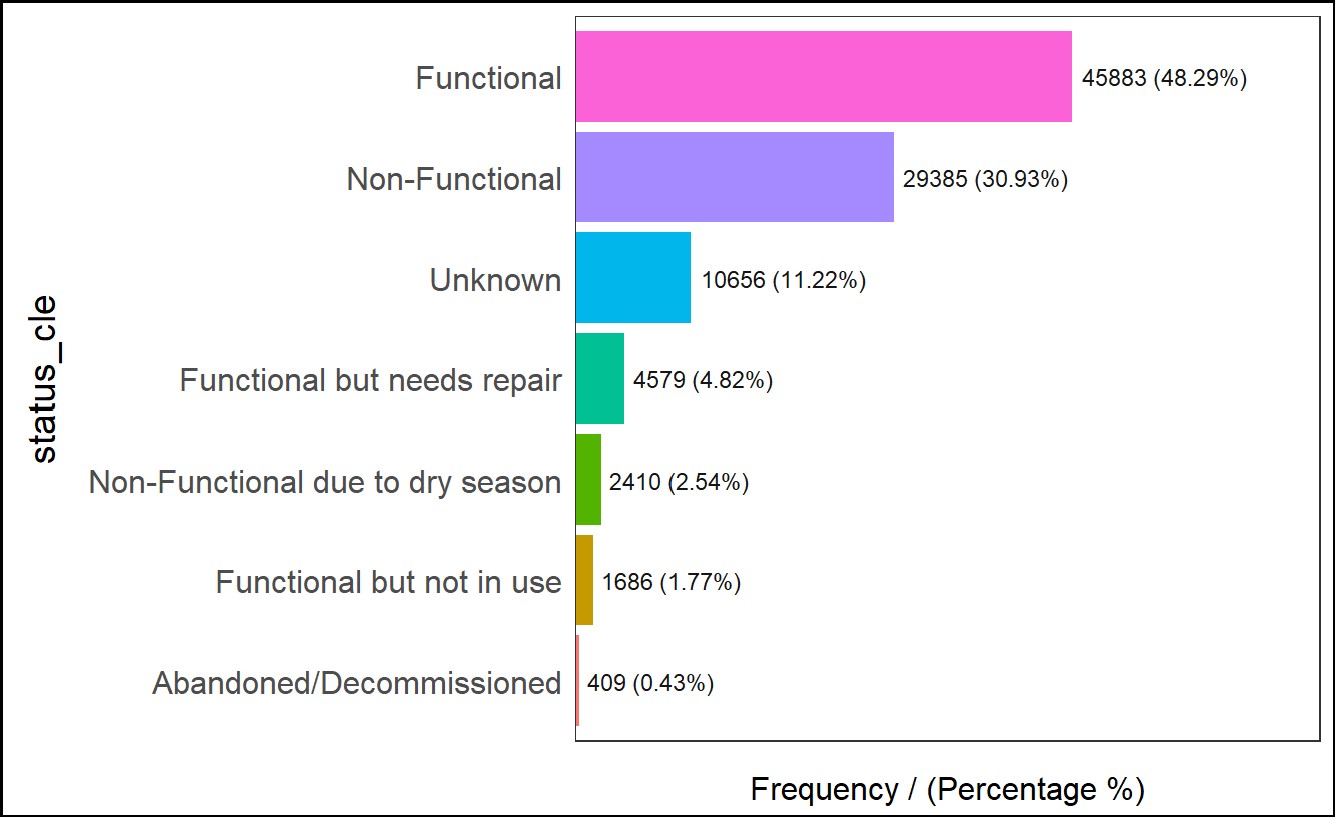
1.4 Extracting Water Point Data
In this section, we will extract the water point records by using classes in status_cle field.
1.4.1 Extracting functional water point
In the code chunk below, filter() of dplyr is used to select functional water points.
wpt_functional <- wp_nga %>%
filter(status_cle %in%
c("Functional",
"Functional but not in use",
"Functional but needs repair"))freq(data = wpt_functional,
input = "status_cle")1.4.2 Extracting non-functional water point
In the code chunk below, filter() of dplyr is used to select non-functional water points.
wpt_nonfunctional <- wp_nga %>%
filter(status_cle %in%
c("Abandoned/Decommissioned",
"Non-Functional",
"Non-Functional due to dry season"))freq(data=wpt_nonfunctional,
input = 'status_cle')1.4.3 Extracting water point with Unknown class
In the code chunk below, filter() of dplyr is used to select water points with unknown status.
wpt_unknown <- wp_nga %>%
filter(status_cle == "Unknown")1.5 Performing Point-in-Polygon Count
nga_wp <- nga %>%
mutate(`total wpt` = lengths(
st_intersects(nga, wp_nga))) %>%
mutate(`wpt functional` = lengths(
st_intersects(nga, wpt_functional))) %>%
mutate(`wpt non-functional` = lengths(
st_intersects(nga, wpt_nonfunctional))) %>%
mutate(`wpt unknown` = lengths(
st_intersects(nga, wpt_unknown)))1.5 Saving the Analytical Data Table
nga_wp <- nga_wp %>%
mutate(pct_functional = `wpt functional`/`total wpt`) %>%
mutate(`pct_non-functional` = `wpt non-functional`/`total wpt`) %>%
select(3:4, 8:10, 15:23)Things to learn from the code chunk above:
mutate()of dplyr package is used to derive two fields namely pct_functional and pct_non-functionalto keep the file size small,
select()of dplyr is used to retain only fields 3, 4, 8, 9, 10, 15, 16, 17, 18, 19, 20, 21, 22,and 23. Fields 3, 4, 8, 9, 10, 15, 16 and 17 captures the different level of geo boundaries in Nigeria. The 4 different boundaries can be seen below;plot(nga_wp[,c(1,3,5,6)])
ADM2_EN: geo-mapping based on local government area (LGA)
ADM1_EN: geo-mapping based on state or federal capital territory
ADM0_EN: geo-mapping based on country
SD_EN: geo-mapping based on senatorial district
Now, that we have the tidy sf data table subsequent analysis. We will save the sf data table into rds format.
write_rds(nga_wp, "data/nga_wp.rds")1.6 Visualizing the Spatial Distribution of Water Points
1.6.1 Visualizing based on Local Government Area (LGA) by Count
nga_wp <- read_rds("data/nga_wp.rds")
total <- qtm(nga_wp, "total wpt")
wp_functional <- qtm(nga_wp, "wpt functional")
wp_nonfunctional <- qtm(nga_wp, "wpt non-functional")
unknown <- qtm(nga_wp, "wpt unknown")
tmap_mode("view")
tmap_arrange(total, wp_functional, wp_nonfunctional, unknown,
asp=1, ncol=2)Based on the above chart, we briefly observe that in terms of functional waterpoints, the north-west zone has the most functional waterpoints, whereas the number of non-functional water-points seems to be scattered all over in Nigeria.
It is interesting to note that while the district Ifelodun has a relatively higher number of functional waterpoints, it also has the highest number of non-functional waterpoints.
In terms of unknown waterpoint statuses it it mostly populated in the north-central zone of Nigeria.
1.6.2 Visualizing based on Local Government Area (LGA) by Quantile
Notice, that areas with high counts of functional waterpoints or high counts of non-functional waterpoints are rather sparse and the number of areas falling in each bucket of number scale are not evenly distributed. This might be misleading in terms of understanding the waterpoint distribution accross Nigeria and instead we will take a look at the distribution based on the quantile.
We run the code below to get the intended geo-visualization:
tmap_mode("view")
total <- tm_shape(nga_wp)+
tm_fill("total wpt", style = "quantile") +
tm_borders()
wp_functional <- tm_shape(nga_wp)+
tm_fill("wpt functional", style = "quantile") +
tm_borders()
wp_nonfunctional <- tm_shape(nga_wp)+
tm_fill("wpt non-functional", style = "quantile") +
tm_borders()
unknown <- tm_shape(nga_wp)+
tm_fill("wpt unknown", style = "quantile") +
tm_borders()
tmap_arrange(total, wp_functional, wp_nonfunctional, unknown,
asp=1, ncol=2)