pacman::p_load(sf, tidyverse, tmap, spdep, funModeling, ggpubr, corrplot,
heatmaply, cluster, factoextra, ClustGeo, GGally)Take-home Exercise 2: Regionalisation of Multivariate Water Point Attributes with Non-spatially Constrained and Spatially Constrained Clustering Methods
1 Overview
The process of creating regions is called regionalisation. A regionalisation is a special kind of clustering where the objective is to group observations which are similar in their statistical attributes, but also in their spatial location. In this sense, regionalization embeds the same logic as standard clustering techniques, but also applies a series of geographical constraints. Often, these constraints relate to connectivity: two candidates can only be grouped together in the same region if there exists a path from one member to another member that never leaves the region. These paths often model the spatial relationships in the data, such as contiguity or proximity. However, connectivity does not always need to hold for all regions, and in certain contexts it makes sense to relax connectivity or to impose different types of geographic constraints.
1.1 Getting Started
1.1.1 Load Packages
For our analysis, we will utilize the following packages:
- Data Wrangling:
sf - for importing and processing geospatial data,
tidyverse - for importing and processing non-spatial data. In this exercise, readr package will be used for importing wkt data and dplyr package will be used to wrangling the data,
- Visualisation:
tmap - for preparation of cartographic quality choropleth map,
funModeling - for rapid Exploratory Data Analysis,
ggpubr - for creating and customizing ‘ggplot2’- based publication ready plots,
corrplot - visual exploratory tool on correlation matrix that supports automatic variable reordering to help detect hidden patterns among variables,
heatmaply - for interactive visualisation of cluster heatmaps,
GGally - extends ggplot2 by adding several functions to reduce the complexity of combining geoms with transformed data
- Correlation and Clustering Analysis:
spdep - for computation of spatial weights, global and local spatial autocorrelation statistics,
cluster - for cluster analysis,
factoextra - to extract and visualise results of multivariate data analyses, and
ClustGeo - implements a Ward-like hierarchical clustering algorithm including spatial/geographical constraints
We will run the following code chunk to load the required packages:
1.1.2 Import Data
1.1.2.1 Importing water point data
wp_nga <- read_csv("data/aspatial/WPdx.csv") %>%
filter(`#clean_country_name` == "Nigeria")Thing to learn from the code chunk above:
The original file name is called Water_Point_Data_Exchange_-_PlusWPdx.csv, has been renamed to WPdx.csv for easy encoding.
Instead of using
read.csv()of Base R to import the csv file into R,read_csv()is readr package is used. This is because during the initial data exploration, we notice that there is at least one field name with space between the field name (ie. New Georeferenced Column)The data file contains water point data of many countries. In this study, we are interested on water point in Nigeria on. Hence,
filter()of dplyr is used to extract out records belong to Nigeria only.
1.1.2.2 Convert wkt data
After the data are imported into R environment, it is a good practice to review both the data structure and the data table if it is in tibble data frame format in R Studio.
Notice that the newly imported tibble data frame (i.e. wp_nga) contains a field called New Georeferenced Column which represent spatial data in a textual format. In fact, this kind of text file is popularly known as Well Known Text in short wkt.
Two steps will be used to convert an asptial data file in wkt format into a sf data frame by using sf.
First, st_as_sfc() of sf package is used to derive a new field called Geometry as shown in the code chunk below.
wp_nga$Geometry <- st_as_sfc(wp_nga$`New Georeferenced Column`)Next, st_sf() will be used to convert the tibble data frame into sf data frame.
The data is currently assigned to the coordinates system of WGS 84 but we require using the CRS of Nigeria with an ESPG code of either 26391, 26392, and 26303. Therefore, we will use the st_transform() function to mapped to the EPSG code of 26391 for our analysis.
wp_nga <- st_sf(wp_nga, crs=4326) %>% st_transform(crs = 26391)
wp_nga1.1.2.3 Importing Nigeria LGA level boundary data
Now, we are going to import the LGA (Local Government Area) boundary data obtained from Humanitarian Data Exchange portal into R environment by using the code chunk below.
nga <- st_read(dsn = "data/geospatial",
layer = "nga_admbnda_adm2_osgof_20190417",
crs = 4326) %>%
st_transform(crs = 26391) %>%
select(3:4,8:9,17)Reading layer `nga_admbnda_adm2_osgof_20190417' from data source
`C:\hulwana\ISSS624\Take-Home_Ex\Take-Home_Ex2\data\geospatial'
using driver `ESRI Shapefile'
Simple feature collection with 774 features and 16 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 2.668534 ymin: 4.273007 xmax: 14.67882 ymax: 13.89442
Geodetic CRS: WGS 841.2 Data Preparation
Before proceeding to the geospatial analysis, we will first prepare the data.
1.2.1 Checking duplicated area names
We will first check if there are any duplicated areas by running the following code chunk:
dup <- nga$ADM2_EN[duplicated(nga$ADM2_EN)]
dup[1] "Bassa" "Ifelodun" "Irepodun" "Nasarawa" "Obi" "Surulere"From the above, we see that areas Bassa, Ifelodun, Irepodun, Nasarawa, Obi and Surulere have duplicated labeling.
We will then plot the duplicated areas to determine and understand where are the areas with duplicated names.
dup_areas <- nga %>%
filter(ADM2_EN %in% dup) %>%
select(ADM2_EN, geometry)
state_borders <- nga %>%
select(ADM1_EN, geometry)
tmap_mode("view")
tm_shape(state_borders) +
tm_fill("ADM1_EN") +
tm_shape(dup_areas) +
tm_polygons("ADM2_EN", alpha = 0.08) +
tm_layout(legend.show = FALSE)tmap_mode("plot")Based on the information gathered in nigeriainfopedia, we realized that the duplication in names exist due to areas having similar names but located in different state. The states at which these areas are located are as follows:
dup_areas_state <- nga %>%
filter(ADM2_EN %in% dup) %>%
select(ADM2_EN, ADM1_EN)
dup_areas_stateSimple feature collection with 12 features and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 99926.41 ymin: 271934.4 xmax: 729231.7 ymax: 893313
Projected CRS: Minna / Nigeria West Belt
First 10 features:
ADM2_EN ADM1_EN geometry
1 Bassa Kogi MULTIPOLYGON (((555599.8 44...
2 Bassa Plateau MULTIPOLYGON (((704592.8 70...
3 Ifelodun Kwara MULTIPOLYGON (((273735.2 55...
4 Ifelodun Osun MULTIPOLYGON (((255291.7 43...
5 Irepodun Kwara MULTIPOLYGON (((305947.5 46...
6 Irepodun Osun MULTIPOLYGON (((235603 4279...
7 Nasarawa Kano MULTIPOLYGON (((677128.6 89...
8 Nasarawa Nasarawa MULTIPOLYGON (((608258.1 51...
9 Obi Benue MULTIPOLYGON (((663064.8 34...
10 Obi Nasarawa MULTIPOLYGON (((727739.2 48...Since these areas have duplicated names, it might result in an inaccurate analysis when they are aggregated together. Therefore the duplicated names have to be recoded by executing the following code chunk:
nga$ADM2_EN[nga$ADM2_EN == "Bassa" & nga$ADM1_EN == "Kogi"] <- "Bassa (Kogi)"
nga$ADM2_EN[nga$ADM2_EN == "Bassa" & nga$ADM1_EN == "Plateau"] <- "Bassa (Plateau)"
nga$ADM2_EN[nga$ADM2_EN == "Ifelodun" & nga$ADM1_EN == "Kwara"] <- "Ifelodun (Kwara)"
nga$ADM2_EN[nga$ADM2_EN == "Ifelodun" & nga$ADM1_EN == "Osun"] <- "Ifelodun (Osun)"
nga$ADM2_EN[nga$ADM2_EN == "Irepodun" & nga$ADM1_EN == "Kwara"] <- "Irepodun (Kwara)"
nga$ADM2_EN[nga$ADM2_EN == "Irepodun" & nga$ADM1_EN == "Osun"] <- "Irepodun (Osun)"
nga$ADM2_EN[nga$ADM2_EN == "Nasarawa" & nga$ADM1_EN == "Kano"] <- "Nasarawa (Kano)"
nga$ADM2_EN[nga$ADM2_EN == "Nasarawa" & nga$ADM1_EN == "Nasarawa"] <- "Nasarawa (Nasarawa)"
nga$ADM2_EN[nga$ADM2_EN == "Obi" & nga$ADM1_EN == "Benue"] <- "Obi (Benue)"
nga$ADM2_EN[nga$ADM2_EN == "Obi" & nga$ADM1_EN == "Nasarawa"] <- "Obi (Nasarawa)"
nga$ADM2_EN[nga$ADM2_EN == "Surulere" & nga$ADM1_EN == "Lagos"] <- "Surulere (Lagos)"
nga$ADM2_EN[nga$ADM2_EN == "Surulere" & nga$ADM1_EN == "Oyo"] <- "Surulere (Oyo)"Check if there are duplicated in LGA names after the clean-up
nga$ADM2_EN[duplicated(nga$ADM2_EN)]character(0)1.3 Data Wrangling
1.3.1 Extract all the required variables and recode if needed
Since we would like to understand if there are any similar characteristics of areas in Nigeria with respect to the availability of water points, we will need to extract the required variables and prepare them. We will first load the data to see what are the fields present by using the glimpse() function.
glimpse(wp_nga)In total there are 71 fields each having 95,008 observations.
The data required for our analysis are:
Total number of functional water points
Total number of nonfunctional water points
Percentage of functional water points
Percentage of non-functional water points
Percentage of main water point technology (i.e. Hand Pump)
Percentage of usage capacity (i.e. < 1000, >=1000)
Percentage of rural water points
Thus we will:
Select the columns #water_tech_category, #status_clean and is_urban
Additional columns selected for consideration: #subjective_quality and usage_capacity
Tidy the name of variables that starts with “#”
wp_rev <- wp_nga %>%
select(10,22,26,46,47) %>%
rename(`water_tech` = `#water_tech_category`, `status_clean` = `#status_clean`,
`quality` = `#subjective_quality` )The freq() function from funModeling package, allows quick visualisation on the count and percentages of each type of categories., as shown below;
freq(data=wp_rev,
input = 'status_clean')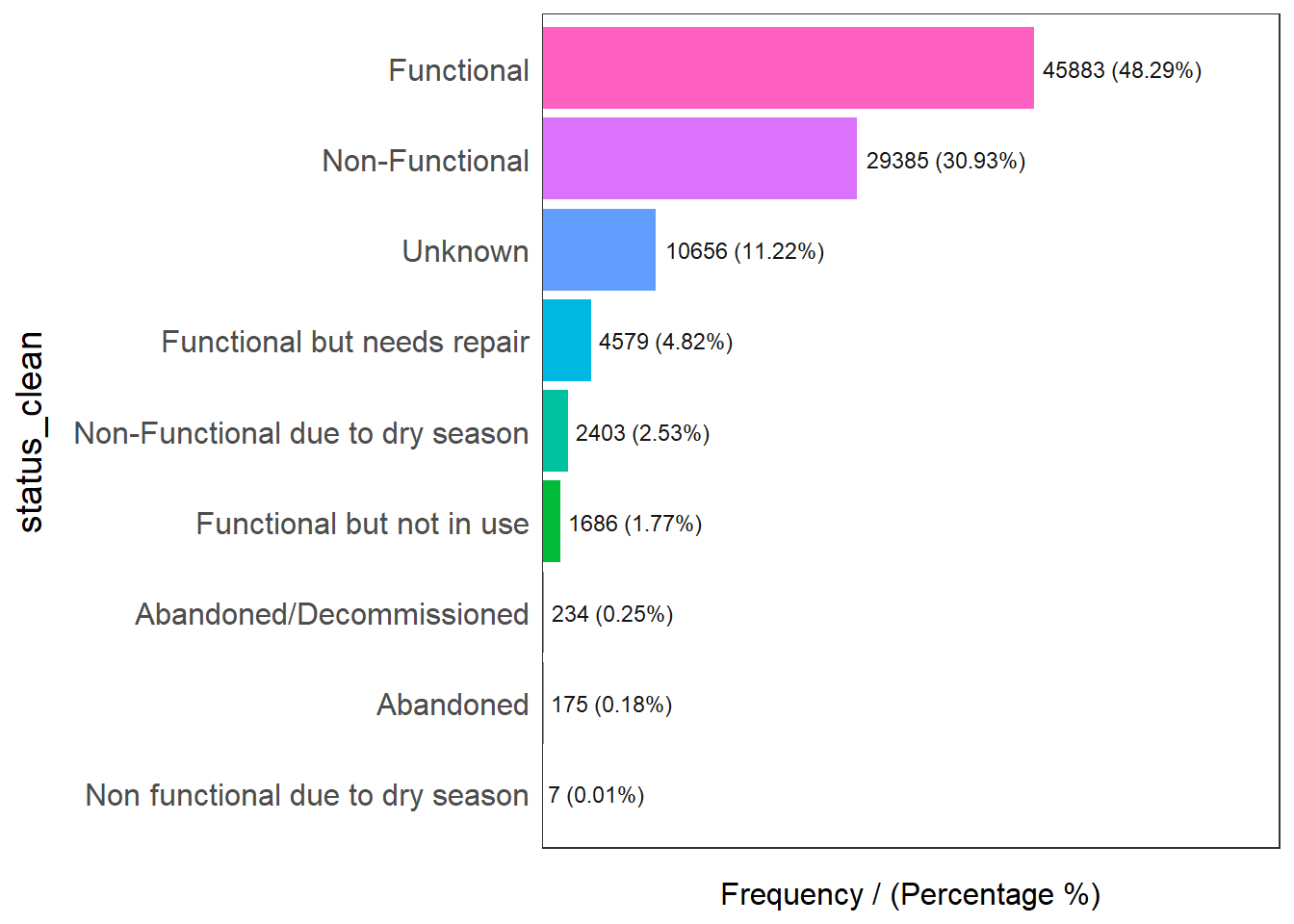
status_clean frequency percentage cumulative_perc
1 Functional 45883 48.29 48.29
2 Non-Functional 29385 30.93 79.22
3 Unknown 10656 11.22 90.44
4 Functional but needs repair 4579 4.82 95.26
5 Non-Functional due to dry season 2403 2.53 97.79
6 Functional but not in use 1686 1.77 99.56
7 Abandoned/Decommissioned 234 0.25 99.81
8 Abandoned 175 0.18 99.99
9 Non functional due to dry season 7 0.01 100.001.3.1.1 Recoding NA values into String
We observed that there are more than 10% of observations that are NAs for this field. Thus, we will recode it into ‘Unknown’.
wp_rev <- wp_rev %>%
dplyr::mutate(status_clean =
replace_na(status_clean, "Unknown"))1.3.2 Extracting Water Point Data
Since, we are interested to know how many functional and non-functional taps there are, we execute the following codes to count the number of functional and non-functional taps as well as calculate the percentages of each type of taps.
For the status_clean variable, we will also re-group the water points into the following categories:
Unknown
Functional
Non-functional
1.3.2.1 Extracting Water Point with Unknown Class
In the code chunk below, filter() of dplyr is used to select water points with unknown status.
wpt_unknown <- wp_rev %>%
filter(status_clean == "Unknown")1.3.2.2 Extracting Functional Water Point
In the code chunk below, filter() of dplyr is used to select functional water points.
We will consider the following categories as functional water points:
Functional
Functional but not in use
Functional but needs repair
wpt_functional <- wp_rev %>%
filter(status_clean %in%
c("Functional",
"Functional but not in use",
"Functional but needs repair"))1.3.2.3 Extracting Non-Functional Water Point
On the other hand, the following categories, will be grouped as non-functional water points:
Non-Functional
Non-Functional due to dry season
Abandoned/Decommissioned
Abandoned
Non functional due to dry season
wpt_nonfunctional <- wp_rev %>%
filter(status_clean %in%
c("Non-Functional",
"Non-Functional due to dry season",
"Abandoned/Decommissioned",
"Abandoned",
"Non functional due to dry season"))1.3.2.4 Performing Point-in-Polygon Count
To count the number of different categories of water points found by LGA, we will utilize the mutate() function for the calculation as shown in the code:
nga_wp <- nga %>%
mutate(`total wpt` = lengths(
st_intersects(nga, wp_rev))) %>%
mutate(`wpt functional` = lengths(
st_intersects(nga, wpt_functional))) %>%
mutate(`wpt non-functional` = lengths(
st_intersects(nga, wpt_nonfunctional))) %>%
mutate(`wpt unknown` = lengths(
st_intersects(nga, wpt_unknown)))1.3.2.5 Compute the Percentages of Water Points
To compute the percentages of functional and non-functional water points, we execute the following code:
nga_wp <- nga_wp %>%
mutate(pct_functional = `wpt functional`/`total wpt`) %>%
mutate(`pct_non-functional` = `wpt non-functional`/`total wpt`)1.3.3 Extracting Water Technology Data
To see what are the different types of water technology present as well as its distribution, we run the following code:
freq(data=wp_rev,
input = 'water_tech')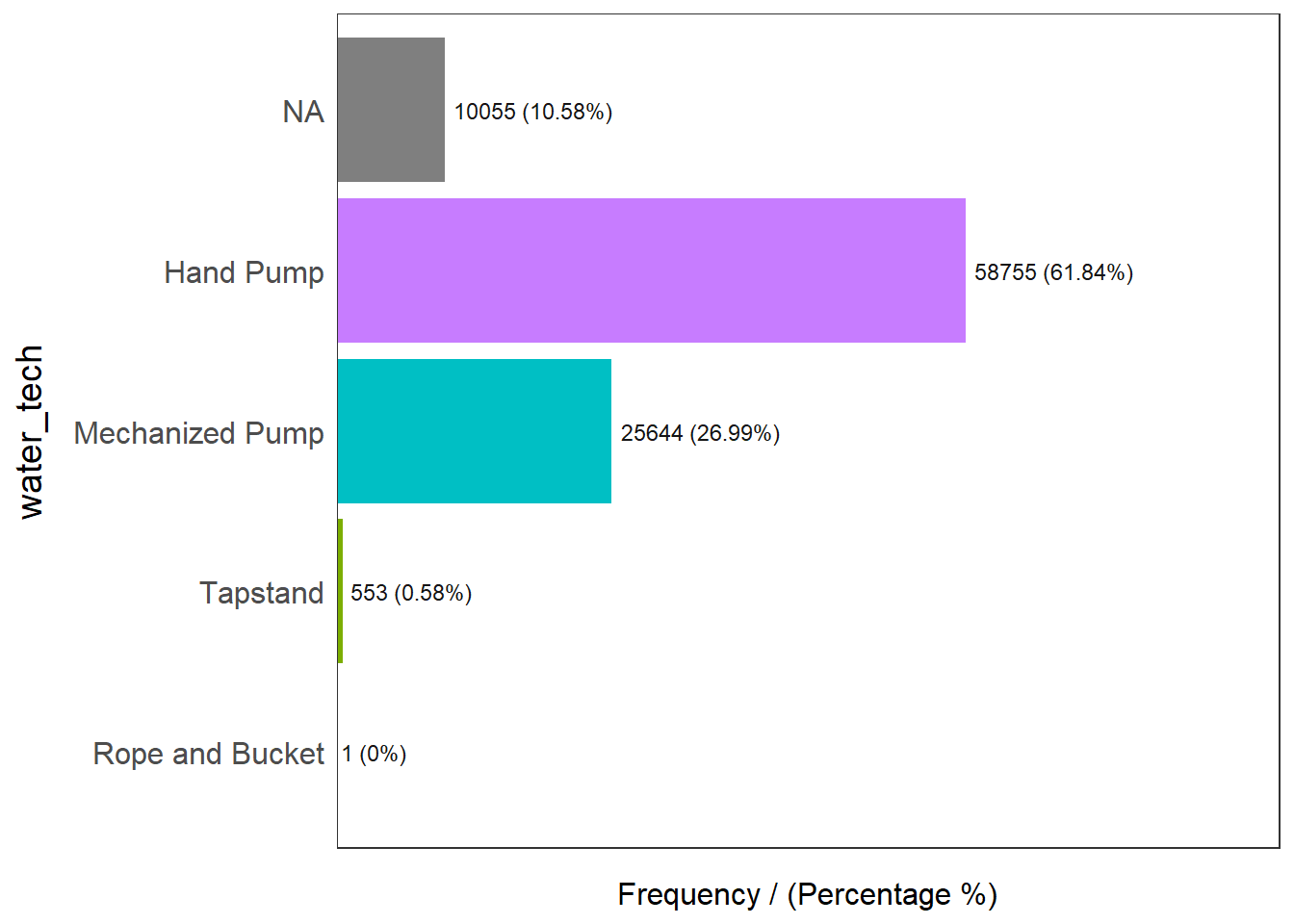
water_tech frequency percentage cumulative_perc
1 Hand Pump 58755 61.84 61.84
2 Mechanized Pump 25644 26.99 88.83
3 <NA> 10055 10.58 99.41
4 Tapstand 553 0.58 99.99
5 Rope and Bucket 1 0.00 100.00Observed that the dominating type of water technology belongs to the ‘Hand Pump’ category at 61.84% of the water points found in Nigeria. As the number of ‘Mechanized Pump’ is substantially large we will also consider the percentage of this type of water point technology in our analysis. The number of water points that are either ‘Tapstand’ and ‘Rope and Bucket’ is too small and thus will not be considered in our analysis.
1.3.3.1 Extracting Hand Pump Water Points
wpt_hand <- wp_rev %>%
filter(water_tech == "Hand Pump")1.3.3.2 Extracting Mechanized Pump Water Points
wpt_mechanized <- wp_rev %>%
filter(water_tech == "Mechanized Pump")1.3.3.3 Performing Point-in-Polygon Count
To count the number of different categories of water point technologies found in each LGA, we will utilize the mutate() function for the calculation as shown in the code:
nga_wp <- nga_wp %>%
mutate(`wpt hand` = lengths(
st_intersects(nga_wp, wpt_hand))) %>%
mutate(`wpt mechanized` = lengths(
st_intersects(nga_wp, wpt_mechanized)))1.3.3.4 Compute the Percentages of Hand Pump and Mechanized Pump Water Points
To compute the percentages of hand pump and mechanized pump water points, we execute the following code:
nga_wp <- nga_wp %>%
mutate(pct_hand = `wpt hand`/`total wpt`) %>%
mutate(`pct_mechanized` = `wpt mechanized`/`total wpt`)1.3.4 Extracting Rural and Urban Areas
To obtain the percentages of rural areas, we extract the data from the is_urban field.
1.3.4.1 Extract data on rural areas
wpt_rural <- wp_rev %>%
filter(is_urban == FALSE)1.3.4.2 Performing Point-in-Polygon Count
To count the number of rural areas found in each LGA, we will utilize the mutate() function for the calculation as shown in the code:
nga_wp <- nga_wp %>%
mutate(`wpt rural` = lengths(
st_intersects(nga_wp, wpt_rural)))1.3.4.3 Compute the Percentages of Rural Areas
To compute the percentages of rural areas, we execute the following code:
nga_wp <- nga_wp %>%
mutate(pct_rural = `wpt rural`/`total wpt`)1.3.5 Extracting Quality
1.3.5.1 Different Categories for Quality
To plot a bar chart on the different categories under the variable quality, we can run the following code:
freq(data=wp_rev,
input = 'quality')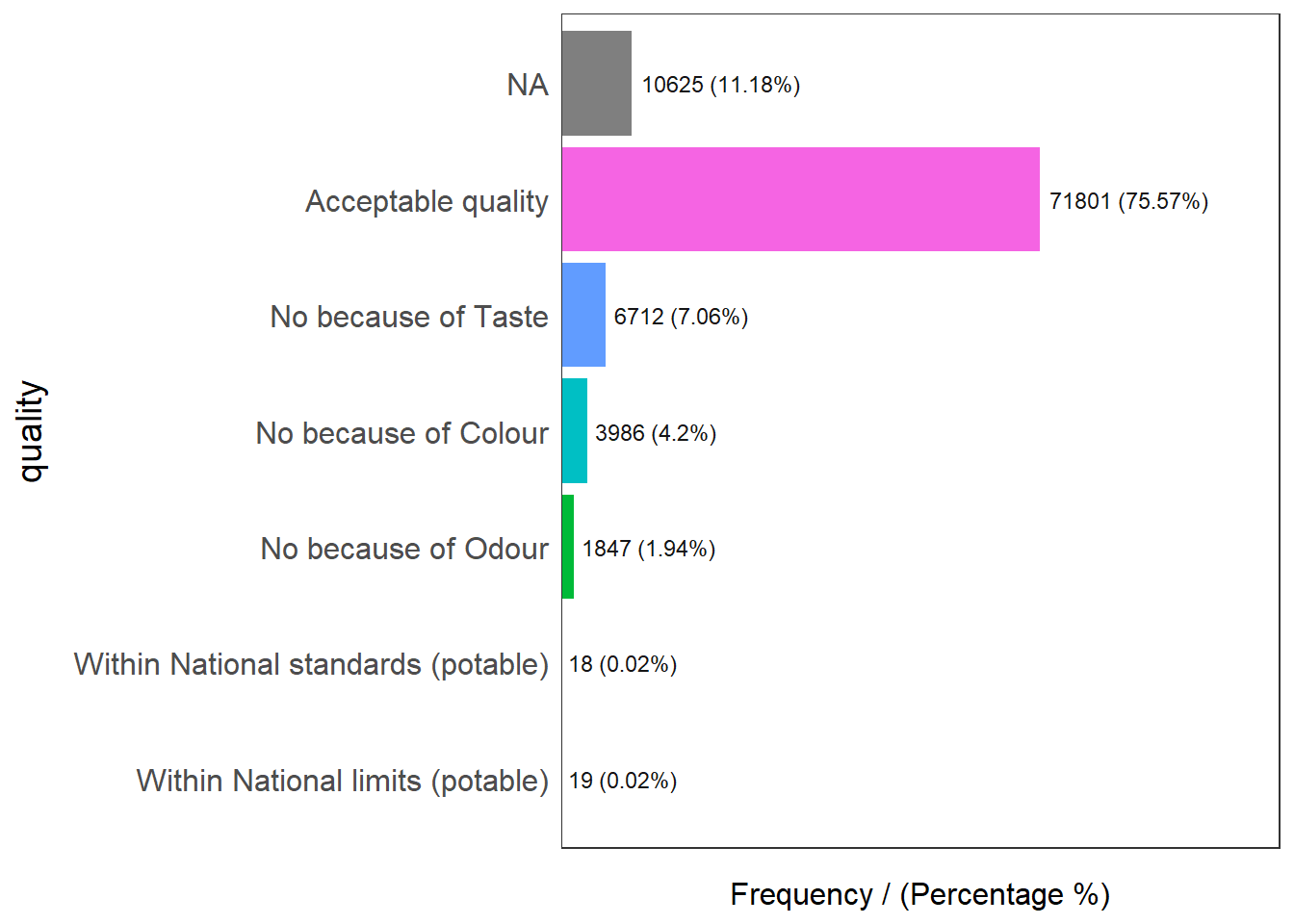
quality frequency percentage cumulative_perc
1 Acceptable quality 71801 75.57 75.57
2 <NA> 10625 11.18 86.75
3 No because of Taste 6712 7.06 93.81
4 No because of Colour 3986 4.20 98.01
5 No because of Odour 1847 1.94 99.95
6 Within National limits (potable) 19 0.02 99.97
7 Within National standards (potable) 18 0.02 100.001.3.5.2 Acceptable Quality
The categories “Acceptable quality”, “Within National standards (potable)” and “Within National limits (potable)” will be classified as acceptable water quality.
wpt_acceptable <- wp_rev %>%
filter(quality %in%
c("Acceptable quality",
"Within National standards (potable)",
"Within National limits (potable)"))1.3.5.3 Unacceptable Quality
Whereas the categories “No because of Taste”, “No because of Colour”, and “No because of Odour” will be classified as unacceptable quality of water.
wpt_unacceptable <- wp_rev %>%
filter(quality %in%
c("No because of Taste",
"No because of Colour",
"No because of Odour"))1.3.5.4 Performing Point-in-Polygon Count
nga_wp <- nga_wp %>%
mutate(`wpt acceptable` = lengths(
st_intersects(nga_wp, wpt_acceptable))) %>%
mutate(`wpt unacceptable` = lengths(
st_intersects(nga_wp, wpt_unacceptable)))1.3.5.5 Compute the Percentages of Acceptable and Unacceptable Water Quality
nga_wp <- nga_wp %>%
mutate(pct_acceptable = `wpt acceptable`/`total wpt`) %>%
mutate(pct_unacceptable = `wpt unacceptable`/`total wpt`)1.3.6 Usage Capacity
1.3.6.1 Extracting Usage Capacity Data
freq(data=wp_rev,
input = 'usage_capacity')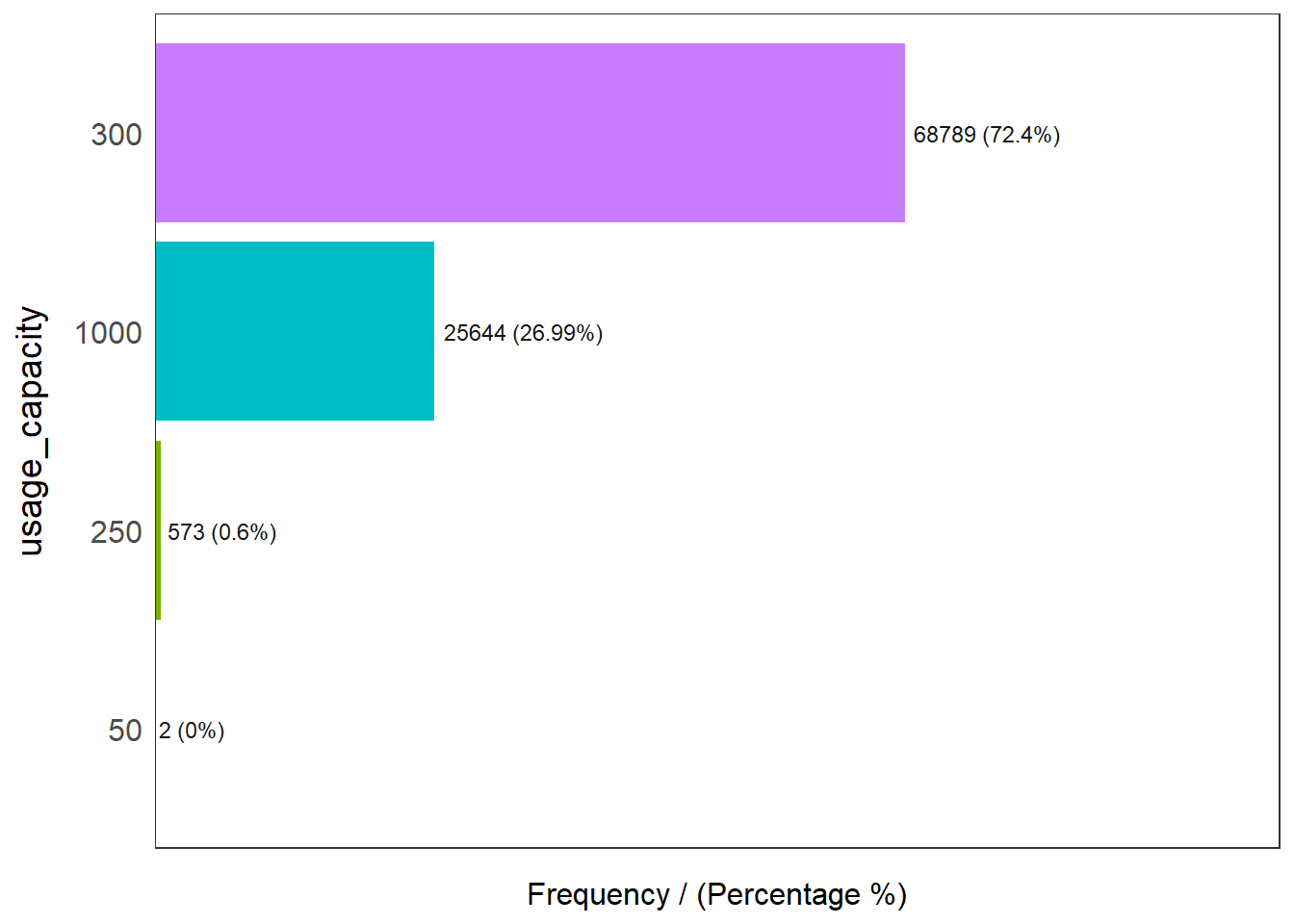
usage_capacity frequency percentage cumulative_perc
1 300 68789 72.40 72.40
2 1000 25644 26.99 99.39
3 250 573 0.60 99.99
4 50 2 0.00 100.00We see that there are 2 groups with substantial number of observations which are 300 and 1000. Thus, we will recode the groups to those with less than or equal to 300 and more than 300.
1.3.6.2 Usage capacity of 300 or lesser
wpt_less300 <- wp_rev %>%
filter(usage_capacity < 301)1.3.6.3 Usage capacity greater than 300
wpt_more300 <- wp_rev %>%
filter(usage_capacity > 300)1.3.6.4 Performing Point-in-Polygon Count
nga_wp <- nga_wp %>%
mutate(`wpt less300` = lengths(
st_intersects(nga_wp, wpt_less300))) %>%
mutate(`wpt more300` = lengths(
st_intersects(nga_wp, wpt_more300)))1.3.6.5 Compute the Percentages of Usage Capacity less than or greater than 301
nga_wp <- nga_wp %>%
mutate(pct_less300 = `wpt less300`/`total wpt`) %>%
mutate(pct_more300 = `wpt more300`/`total wpt`)1.3.7 Saving Data
We will then save the cleaned data in rds format.
write_rds(wp_rev, "data/wp_rev.rds")
write_rds(nga, "data/nga.rds")
write_rds(nga_wp, "data/nga_wp.rds")2 Exploratory Data Analysis
2.1 Summary Statistics
Let us review the summary statistics of the newly derived penetration rates using the code chunk below.
summary(nga_wp) ADM2_EN ADM2_PCODE ADM1_EN ADM1_PCODE
Length:774 Length:774 Length:774 Length:774
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
geometry total wpt wpt functional wpt non-functional
MULTIPOLYGON :774 Min. : 0.0 Min. : 0.00 Min. : 0.00
epsg:26391 : 0 1st Qu.: 45.0 1st Qu.: 17.00 1st Qu.: 12.25
+proj=tmer...: 0 Median : 96.0 Median : 45.50 Median : 34.00
Mean :122.7 Mean : 67.36 Mean : 41.60
3rd Qu.:168.8 3rd Qu.: 87.75 3rd Qu.: 60.75
Max. :894.0 Max. :752.00 Max. :278.00
wpt unknown pct_functional pct_non-functional wpt hand
Min. : 0.00 Min. :0.0000 Min. :0.0000 Min. : 0.00
1st Qu.: 0.00 1st Qu.:0.3333 1st Qu.:0.2211 1st Qu.: 6.00
Median : 0.00 Median :0.4792 Median :0.3559 Median : 47.00
Mean : 13.76 Mean :0.5070 Mean :0.3654 Mean : 75.89
3rd Qu.: 17.75 3rd Qu.:0.6749 3rd Qu.:0.5082 3rd Qu.:111.00
Max. :219.00 Max. :1.0000 Max. :1.0000 Max. :764.00
NA's :13 NA's :13
wpt mechanized pct_hand pct_mechanized wpt rural
Min. : 0.00 Min. :0.0000 Min. :0.0000 Min. : 0.00
1st Qu.: 11.00 1st Qu.:0.1860 1st Qu.:0.1250 1st Qu.: 23.00
Median : 25.50 Median :0.5255 Median :0.3193 Median : 64.00
Mean : 33.12 Mean :0.4956 Mean :0.3818 Mean : 97.45
3rd Qu.: 46.00 3rd Qu.:0.7857 3rd Qu.:0.5843 3rd Qu.:141.00
Max. :245.00 Max. :1.0000 Max. :1.0000 Max. :894.00
NA's :13 NA's :13
pct_rural wpt acceptable wpt unacceptable pct_acceptable
Min. :0.0000 Min. : 0.00 Min. : 0.0 Min. :0.0000
1st Qu.:0.5922 1st Qu.: 28.00 1st Qu.: 3.0 1st Qu.:0.5595
Median :0.8717 Median : 71.00 Median : 9.0 Median :0.7759
Mean :0.7395 Mean : 92.79 Mean : 16.2 Mean :0.7172
3rd Qu.:1.0000 3rd Qu.:127.00 3rd Qu.: 21.0 3rd Qu.:0.9221
Max. :1.0000 Max. :833.00 Max. :225.0 Max. :1.0000
NA's :13 NA's :13
pct_unacceptable wpt less300 wpt more300 pct_less300
Min. :0.00000 Min. : 0.00 Min. : 0.00 Min. :0.0000
1st Qu.:0.04124 1st Qu.: 16.00 1st Qu.: 11.00 1st Qu.:0.4157
Median :0.10526 Median : 60.00 Median : 25.50 Median :0.6807
Mean :0.15565 Mean : 89.59 Mean : 33.12 Mean :0.6182
3rd Qu.:0.21429 3rd Qu.:127.75 3rd Qu.: 46.00 3rd Qu.:0.8750
Max. :1.00000 Max. :767.00 Max. :245.00 Max. :1.0000
NA's :13 NA's :13
pct_more300
Min. :0.0000
1st Qu.:0.1250
Median :0.3193
Mean :0.3818
3rd Qu.:0.5843
Max. :1.0000
NA's :13 2.2 EDA using Histogram
Here, we take a look at the distribution of the percentages variable
functional <- ggplot(data=nga_wp,
aes(x= `pct_functional`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
nonfunctional <- ggplot(data=nga_wp,
aes(x= `pct_non-functional`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
hand <- ggplot(data=nga_wp,
aes(x= `pct_hand`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
mechanized <- ggplot(data=nga_wp,
aes(x= `pct_mechanized`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
rural <- ggplot(data=nga_wp,
aes(x= `pct_rural`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
acceptable <- ggplot(data=nga_wp,
aes(x= `pct_acceptable`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
unacceptable <- ggplot(data=nga_wp,
aes(x= `pct_unacceptable`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
less300 <- ggplot(data=nga_wp,
aes(x= `pct_less300`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
more300 <- ggplot(data=nga_wp,
aes(x= `pct_more300`)) +
geom_histogram(bins=20,
color="black",
fill="light blue")
ggarrange(functional, nonfunctional, hand, mechanized, acceptable, unacceptable,
less300, more300, rural,
ncol = 3,
nrow = 3)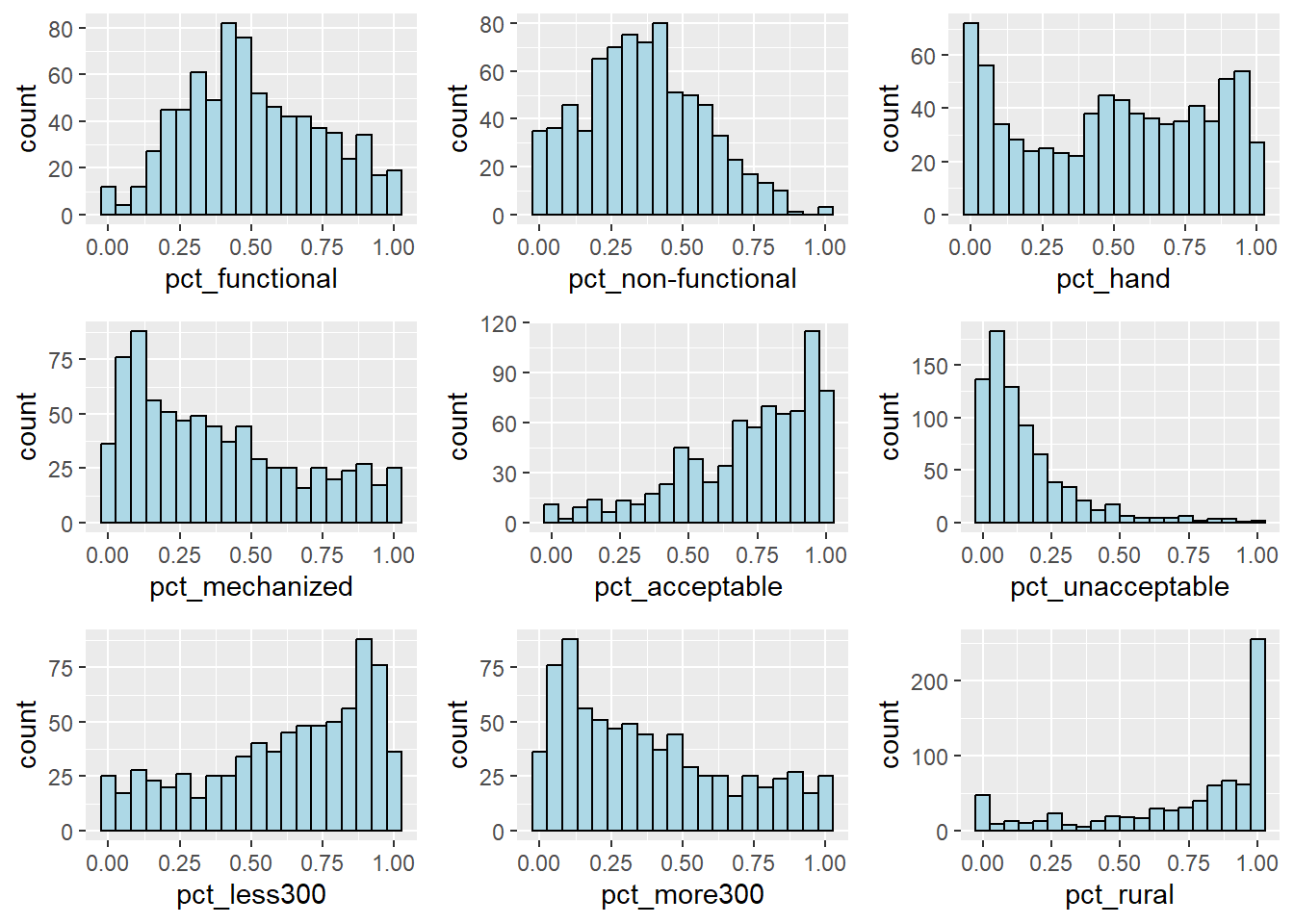
Notice that the variables pct_acceptable, pct_less300 and pct_rural are skewed to the left. Whereas, variables pct_mechanized, pct_unacceptable and pct_more300 are skewed to the right.
2.3 EDA using Choropleth Map
2.3.1 Total Water Points
qtm(nga_wp, "total wpt")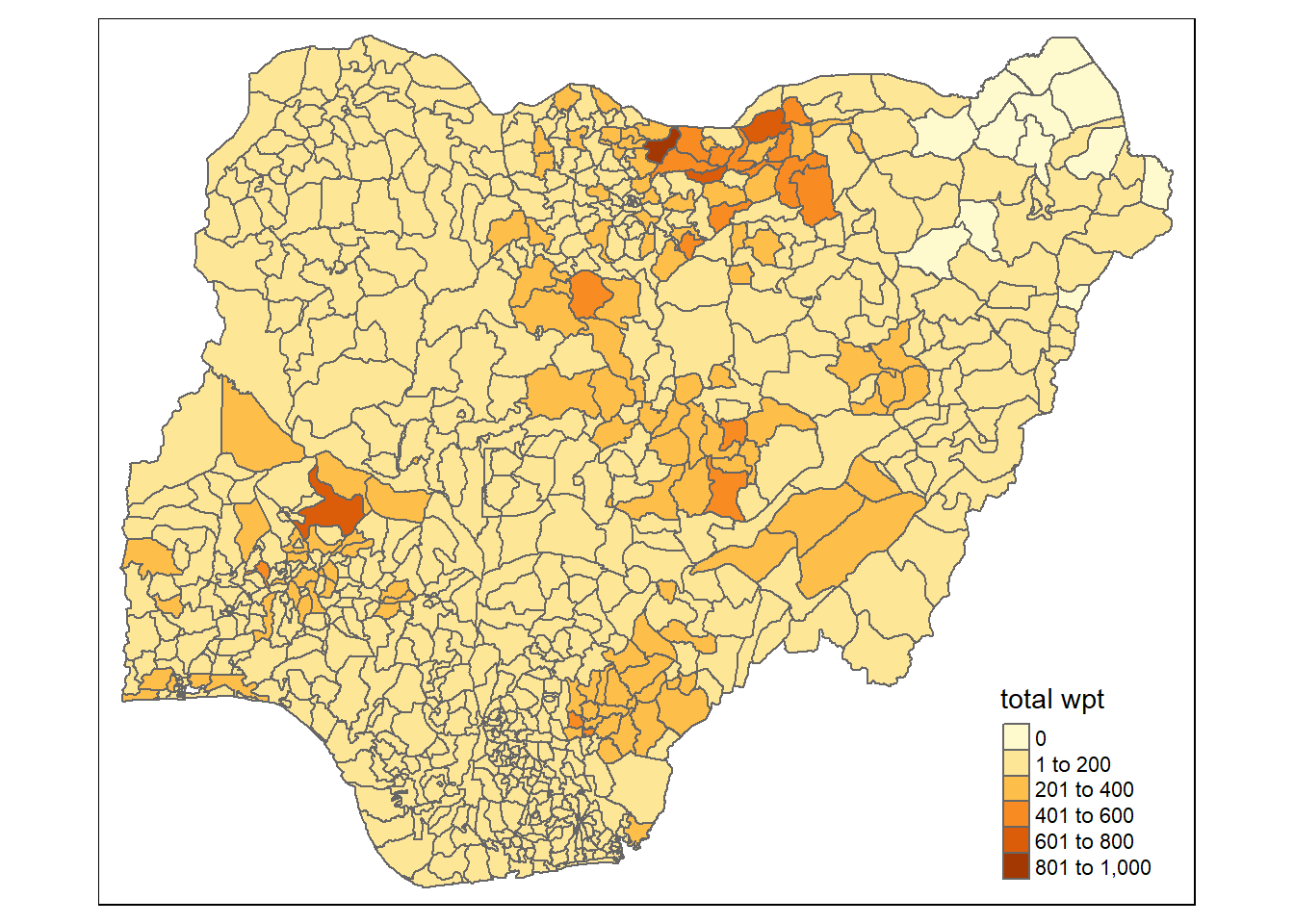
From the above map, we notice that there are a number of areas in the north-eastern part of Nigeria in which there 0 data on the number of water points.
2.3.2 Distribution of Functional and Non-functional Water Points by Percentages
tmap_mode("view")
pct_functional <- tm_shape(nga_wp) +
tm_fill("pct_functional") +
tm_borders()
pct_nonfunctional <- tm_shape(nga_wp) +
tm_fill("pct_non-functional") +
tm_borders()
tmap_arrange(pct_functional, pct_nonfunctional,
asp = 1, ncol = 2,
sync = TRUE)tmap_mode("plot")In terms of functional water points, areas in the northern region have high percentages in comparison to other parts in Nigeria, while in terms of non-functional water points, areas in southern part of Nigeria tended to have higher percentages.
2.3.3 Distribution of Hand Pump and Mechanized Pump by Percentages
tmap_mode("view")
pct_hand <- tm_shape(nga_wp) +
tm_fill("pct_hand", palette = "BuGn") +
tm_borders()
pct_mechanized <- tm_shape(nga_wp) +
tm_fill("pct_mechanized", palette = "BuGn") +
tm_borders()
tmap_arrange(pct_hand, pct_mechanized,
asp = 1, ncol = 2,
sync = TRUE)tmap_mode("plot")We see a similar trend to that of the distribution of functional and non-functional water points, where the norther regions of Nigeria tend to have higher percentages of hand pump but lower percentage of mechanized pump whereas southern regions of Nigeria tended to have higher percentages of mechanized pumps but lower percentages of hand pumps. Perhaps this could be attributed to the technology and development of the different regions and therefore we should proceed to look if there is a similar trend in terms of rural areas.
2.3.4 Distribution of Rural Areas by Percentages
tmap_mode("view")
tm_shape(nga_wp) +
tm_fill("pct_rural", palette = "YlGn") +
tm_borders(col = "black", lwd = 2)